很多业内人士已经注意到,似乎 DeepSeek-R1 等开源模型,在回答问题时往往缺乏 「节制」。尤其是简单问题,它想得过于复杂了。它的单位 token 成本的 API 价格优势,最终将可能被不受制约的 「冗长思考」 所侵蚀。
NousResearch 团队一项研究,就是想搞清楚,开源权重模型在完成相同任务时,是否系统性地需要比闭源模型更多的 token?当将 token 消耗数量纳入考量后,这种差异如何影响总体推理成本?这种效率差异在不同的任务类型中是否更加显著?
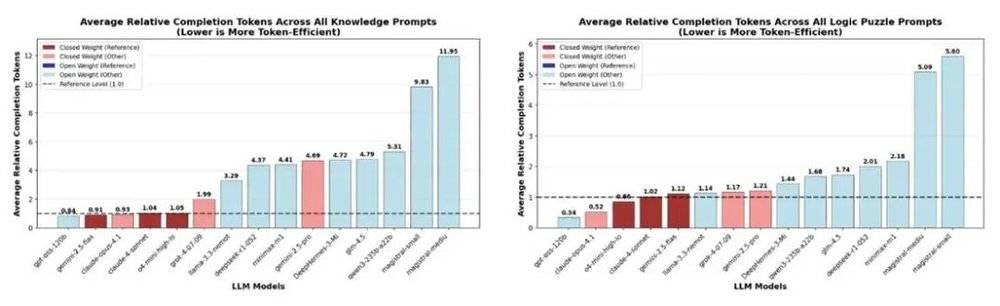
该研究发现,对于不需要复杂推理就可直答的知识题 (Knowledge questions),开源模型的 「浪费」 最为明显,DeepSeek-R1-0528 完成任务消耗的 token 数量 (completion tokens)——它既包括向用户呈现的输出结果,也包括思维链 (CoT),并与实际计费的 token 数量相匹配——要比基准水平高出 4 倍。
不过,到了需要推理数学题 (Math problems)以及更复杂的逻辑谜题 (Logic puzzles),DeepSeek-R1-0528 消耗的 token 数量,高出基准水平缩小至 2 倍左右。看来实际工作中,向合适的模型询问合适的问题是一大学问。
事实上,AI 招聘独角兽公司 Mercor 的另一项独立研究也注意到了这一现象。在它提出的衡量大模型的 AI 生产力指数的 APEX-v1.0 基准上,Qwen-3-235B 和 DeepSeek-R1 的输出长度都超过了其他前沿模型。它们思考得更久,可以弥补一些不足,提升了平均成绩,代价就是更多的 token 消耗。
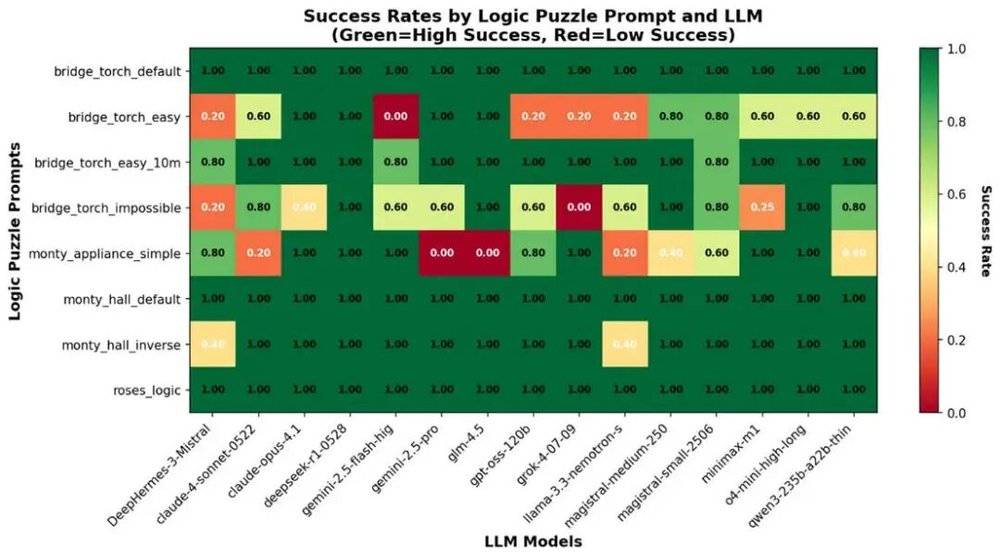
但这也是 「慢思考」 刚推出时的魅力,不是吗?在预训练扩展边际放缓后,测试时扩展越来越重要,是提升解题能力的关键。回到 NousResearch 团队的研究上,DeepSeek-R1 在各类逻辑谜题的准确率,也明显胜出一筹。也许它慢了一些,用的 token 也多了一些,但答对了题!
所以,开源模型相比前沿闭源模型,究竟经济不经济?
如果有一个最简易的统计公式,那么 token 经济可以归纳为:AI 完成一项任务的收益=token 兑现的价值-单位 token 成本×消耗 token 数量。
Token 兑现的价值,一方面取决于模型能不能最终解决现实问题,另一方面则取决于它所解决的问题有多值钱。它下围棋战胜世界冠军,值多少钱?获得奥数金牌,又值多少钱?但更重要的是,在实际工作场景中创造出经济价值,而这些价值由市场来决定。
单位 token 成本也决定着模型的经济性。黄仁勋一直鼓吹 「买得越多,省得越多」,就是从硬件与基础设施层面优化能效,降低运营成本的逻辑。这是美国的强项。目前,美国几乎所有 AI 云巨头与前沿大模型厂商,都在探索与部署 AI 定制芯片以降低推理成本。英伟达计划自研 HBM 基础裸片 (Base Die),OpenAI 则找上了 SK 海力士与三星合作;闪迪甚至预见了数年后高带宽闪存 HBF 的颠覆性。
中国开源社区的贡献,主要在于算法和架构的改进,对 MOE 推理与注意力机制的探索层出不穷。阿里巴巴的 Qwen3-Next 架构,总参数 80B,却只需激活 3B,即可媲美旗舰版 Qwen3-235B 性能,效率大幅提升。DeepSeek 最新发布的 V3.2-Exp 引入了 DSA 机制,能在成本更低的同时几乎不影响模型的输出效果。这些都体现为每百万 token 的输入和输出成本在持续下降。
微软近期一篇为自己的碳足迹 「洗白」 的论文中,驳斥过往的纸面研究,往往忽略了实际部署环境中的规模效应与软硬件优化措施。论文提到,就每次 AI 查询而言,实际能耗要比预估低 8-20 倍。其中,硬件改进带来 1.5 至 2 倍降幅,模型改进带来 3 至 4 倍降幅,工作负载优化带来 2 至 3 倍降幅。
这里的工作负载优化,既包括 KV 缓存管理与批大小管理等提升单位 token 生成效率的手段,也包括用户手动设置 token 预算上限,或自动触发智能路由调用合适模型等降低 token 消耗数量的技术。OpenAI 坚持让实时路由系统,根据对话类型、复杂度、所需工具和明确意图快速决定调用哪个模型。字节跳动的 Knapsack RL 也是类似的预算分配策略探索。这些都是出于性价比的考虑。
很长一段时间以来,在讨论 token 经济学时,完成任务的 token 消耗数量,往往被人们所忽视。这一指标缺乏前述各类测评 token 价值的基准,也不在大模型 API 定价中直接标识出来。
但它无疑越来越重要,它决定着 AI 的经济性。实际工作不同于刷榜 (有的刷榜也有算力成本上限),往往存在明显的成本约束。前述微软论文也担心,随着多模型与智能体的广泛落地,更多的推理次数和更长的推理时间将带来更高的能耗。
不仅如此,要输出更多 token,通常也意味着更长的响应时间,用户体验下降;对于部分必须高速精准响应的场景,这甚至是生死问题;单次任务越来越多的 token 消耗,也可能耗尽模型的上下文窗口,限制它处理复杂长任务的能力。
受限于各自的技术储备、供应链体系与电力供给条件,中国与美国在 token 经济学上已经各自分岔。中国开源模型的首要目标是在国产替代的现实中逼近前沿水平,用较多的 token 换取较高的价值;美国闭源模型则要开始想法设法去降低 token 的消耗,并提升 token 的价值。
从 DeepSeek 的 R1 到 R1-0528,或者,从 Qwen3-235B-A22B-thinking 到 Qwen-235B-A22B-thinking-2507,中国领先的开源模型的迭代,往往伴随着总 token 消耗的上升。而 Anthropic、OpenAI 与 xAI 的模型迭代,则伴随着总 token 消耗的降低。
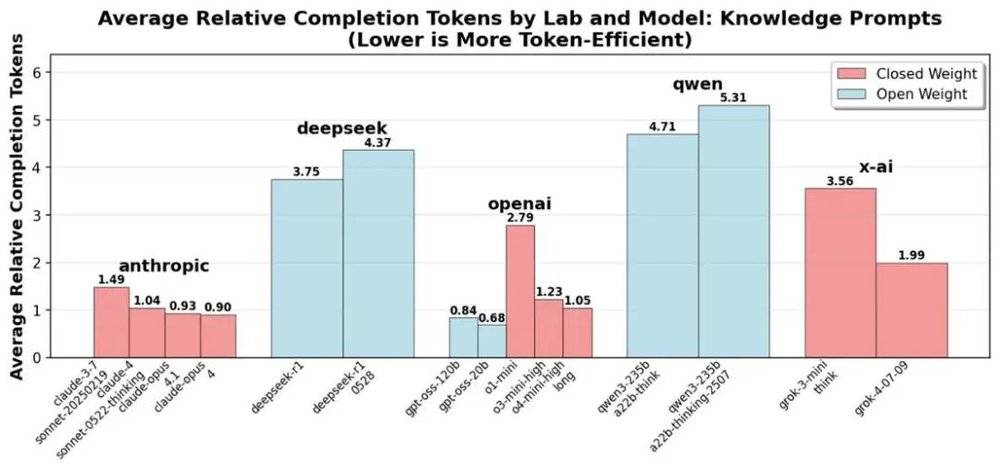
到目前为止,NousResearch 团队的研究认为,综合 token 消耗数量与单位 token 成本 (基于海外第三方的 API 价格,因工作负载不同,定价区间差别较大),DeepSeek 等开源模型仍具备整体成本优势,但在最高 API 定价时 (即以更大的上下文或更高的吞吐速度交付结果等),它的整体成本优势已经不再显著,尤其是在回答简单问题时。
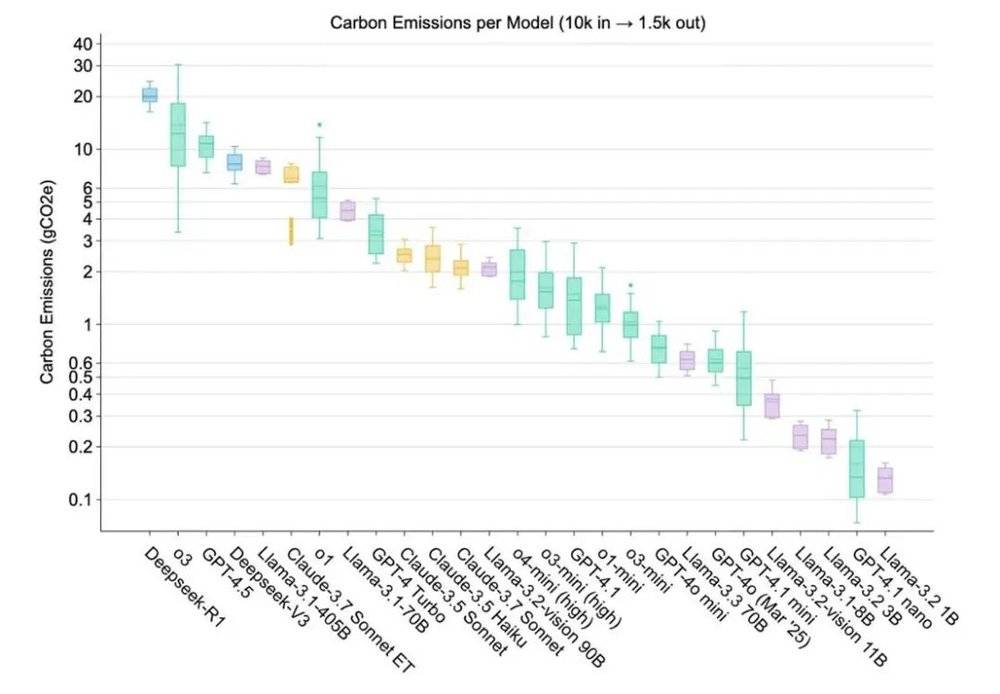
结合中国的 AI 算力生态,token 消耗过多的短板会进一步放大。有一项研究,专门就基础设施的框架,量化了前沿模型的硬件配置与环境乘数,对能耗、水与碳足迹的影响。在其设定场景下,DeepSeek-R1 成为了碳排放量最高的前沿模型,且远高于其他模型。除了与 o3 类似,它大量依赖 CoT 深度思考,还因为该研究为它 「分配」 了 H800 等更低能效的芯片,以及更高 PUE 的数据中心。
当下对性能的追求压倒了一切。最终,起作用的将是 AI 的经济性,用尽可能少的 token 解决尽可能有价值的问题。
参考:
https://doi.org/10.48550/arXiv.2505.09598
https://doi.org/10.48550/arXiv.2509.20241
https://arxiv.org/html/2509.25721v2
https://github.com/cpldcpu/LRMTokenEconomy/