

【旭才科技】2 月 27 日消息,DeepSeek 开源周第四日,DeepSeek 开源了并行优化策略 (Optimized Parallelism Strategies),一次开源了 3 项:
DualPipe:一种用于 V3/R1 模型训练中实现计算与通信重叠的双向流水线并行算法
EPLB:一个针对 V3/R1 的专家并行负载均衡工具
Profile-data:训练和推理框架的分析数据
GitHub 地址:
https://github.com/deepseek-ai/DualPipe
https://github.com/deepseek-ai/eplb
https://github.com/deepseek-ai/profile-data
一、DualPipe
DualPipe 是 DeepSeek-V3 技术报告中提出的一种创新双向流水线并行算法。
它能够实现前向与后向计算和通信阶段的完全重叠,同时有效减少流水线气泡 (空闲时间)。
DeepSeek 展示了在 8 个流水线并行阶段和 20 个 micro-batches 情况下,DualPipe 在两个方向上的调度示例。(来自 DeepSeek-V3 技术报告)

反向方向的微批次与前向方向对称,为了简化图示,这里省略了反向方向的批次 ID。图中由同一个黑色边框包围的两个单元格具有相互重叠的计算和通信。
流水线气泡与内存使用比较
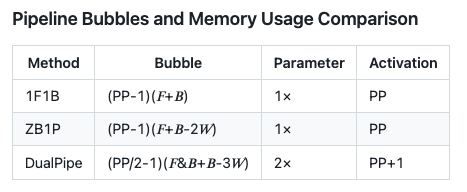
表中,F 代表前向块 (forward chunk) 的执行时间,B 代表完整后向块 (full backward chunk) 的执行时间,W 代表权重后向 (backward for weights) 块的执行时间,而 F&B 则表示同时执行且相互重叠的前向和后向块的执行时间。
DualPipe 显著减少了管道气泡 (空闲时间),表现出效率优势。
二、专家并行负载均衡器 (EPLB)
在使用专家并行 (EP) 时,不同的专家模块会被分配到不同的 GPU 上。由于各个专家的计算负载会随当前任务而变化,因此保持各 GPU 间负载均衡至关重要。
如 DeepSeek-V3 论文所述,研究人员采用了冗余专家 (redundant experts) 策略,对高负载专家进行复制。
为了便于复制和部署,DeepSeek 团队在 eplb.py 中开源了部署的 EP 负载平衡算法。该算法根据估计的专家负载计算平衡的专家复制和放置计划。
请注意,专家负载的具体预测方法不在此代码库的讨论范围内,一种常用的方法是采用历史统计数据的滑动平均值。
算法
负载平衡算法附带了两种用于不同情况的策略。
分层负载平衡 (Hierarchical Load Balancing)
当服务器节点的数量除以专家组的数量时,使用分层负载平衡策略来利用组受限的专家路由。首先将专家组平均打包到节点上,确保不同节点的负载平衡。然后,在每个节点内复制专家。最后,将复制的专家打包到单独的 GPU 上,以确保不同的 GPU 负载平衡。分层负载平衡策略可以在预填充阶段使用较小的专家并行规模。
全局负载平衡 (Global Load Balancing)
在其他情况下,使用全局负载平衡策略,该策略在全局范围内复制专家,而不管专家组如何,并将复制的专家打包到单个 GPU 中。该策略可以在具有较大专家并行规模的解码阶段采用。
三、DeepSeek 基础设施中的数据分析:Profile-data
DeepSeek 公开分享来自训练和推理框架的性能剖析数据,旨在帮助社区更深入地理解通信与计算重叠策略以及相关底层实现细节。
这些剖析数据是通过 PyTorch Profiler 工具获取的。
开发者可以下载后在 Chrome 浏览器中访问 chrome://tracing(或在 Edge 浏览器中访问 edge://tracing) 直接进行可视化查看。
需要说明的是,为了便于剖析,研究人员模拟了一个完全均衡的 MoE 路由策略。
同时,DeepSeek 还公开了这些数据的训练和推理过程。
